I always was curious to see how running ads on my blog will turn out, and how much money I was going to make, and how the amount of traffic received would impact these numbers.
So, I decided to put them on after I moved the blog to my own server. I went for the classic, and I have installed google adsense plugin. Due to the fact that now I pay the server, I was wondering if I could bring the blog into a self-sufficient state, i.e. where it was making enough money to pay its own server. (The server is a digital ocean 5$/month, which runs also other little hobby projects, so it’s not that expensive).
Let’s see the numbers
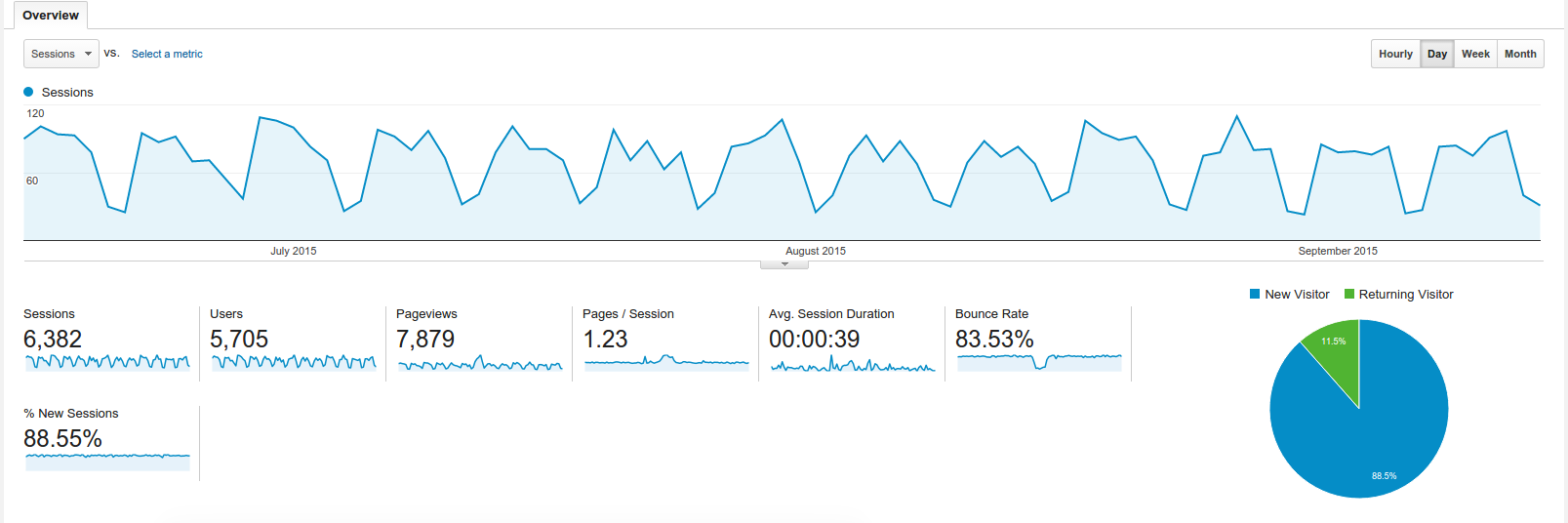
Visitors on Train of Thoughts on the same period covered by the ads
As you can see from the graphs, this blog scores around 120 sessions per day, with mostly new user coming from google, with a massive drop during the WE.
Most of this traffic is composed by technical users, who are looking for one post in specific. They tend to read it, and then they go about their own business.
In the same period this is what the Google AdSense income looks like:
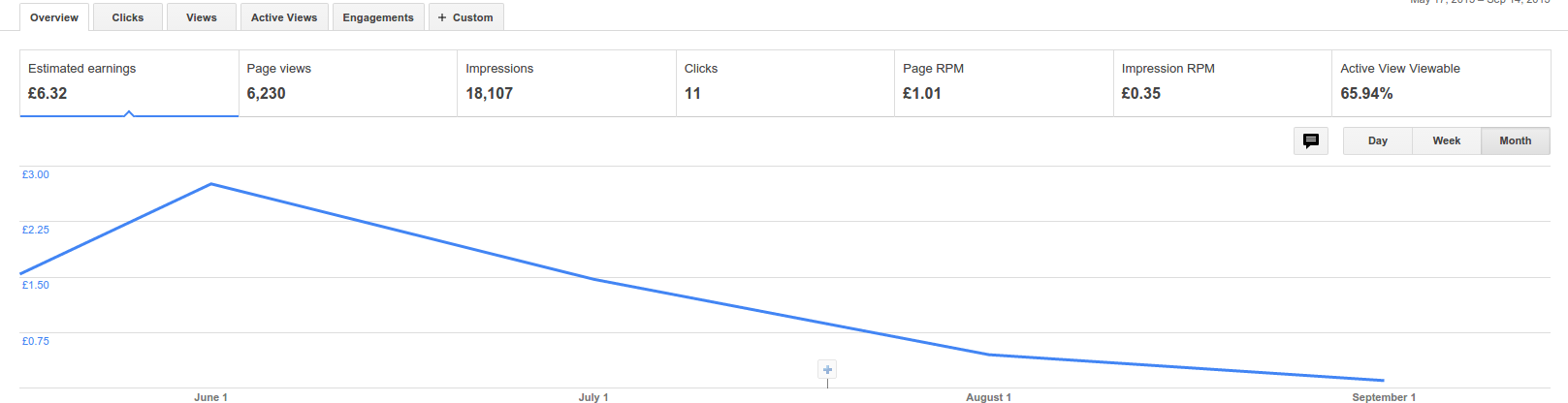
Google AdSense gain during the same period
The estimated earnings is what is interesting: running this ads on this blog has summed up to a whopping £6.32. Considering that google will only pay when £60 is reached, I can expect to see the payments in more or less 3 years. W00t?
I was wondering if this is because everybody runs AdBlock, and the ads are always shielded. To discover this I have added a plugin to keep track of this, and you can see below how it looks like:
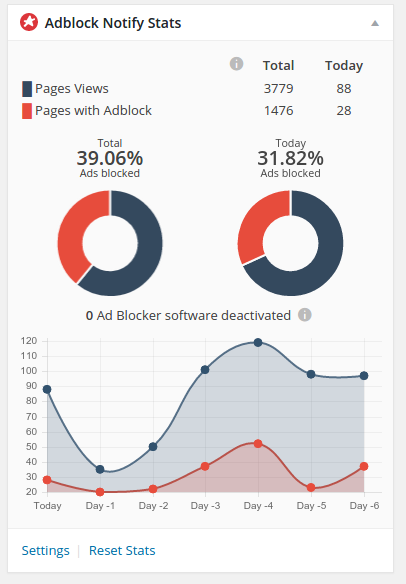
40% with AdBlock on! And no one deactivates it!
From the data I’ve got, it seems there are 40% of the people with AdBlock on, and it seems no-one, so far, read my message and decided to white list the website. It can be concluded that 60 sessions (the one withoput AdBlock running), achieved only during peak days, do not bring any kind of decent income.
I had ads on top of the post, on the sidebar and also between the posts. They were very prominent and were really annoying, but I thought they were going to pay for the server, so they were a necessary evil. I guess we can conclude that this is not the case.
Different strategy
Given this situation, I’ve decided to slash the ads severely and leave only one in the sidebar, and with colour that integrates in the site and it does not look too much alien, hopefully.
I do not expect people to click on it, or to increase the revenue, however I am more happy about the state of the blog, with less clutter and visual noise adding up, and a more gratifying and pleasant navigation. We’ll see how it goes.
Happy reading!