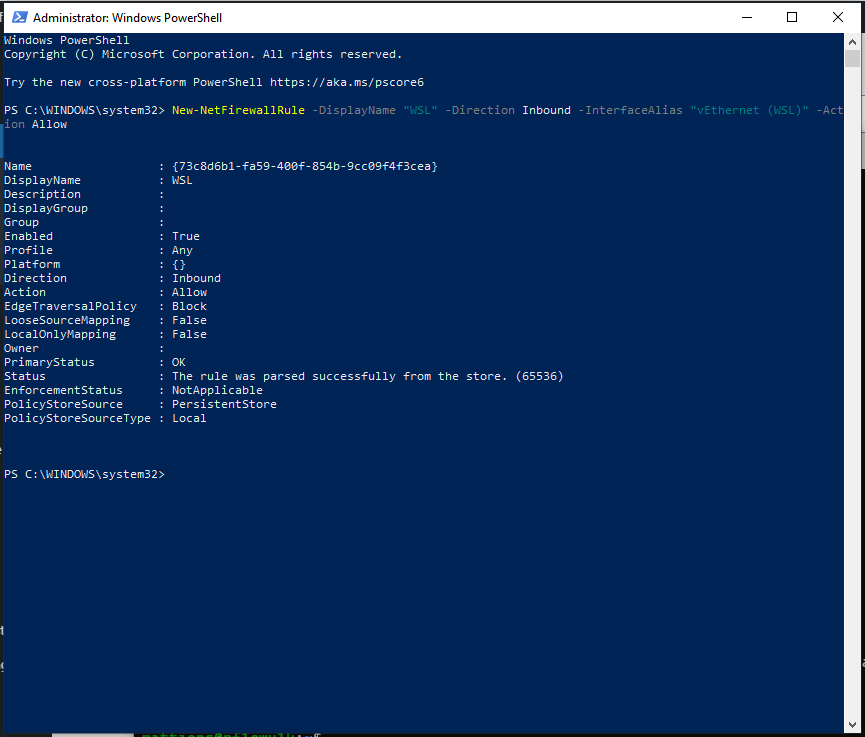
Usually in this blog, especially lately, I stick to technology and related topics, however this episode was so funny for me that I’ve decided to write about it even if it is a page from my personal life.
Have fun!

I left the house this morning with the idea of getting a small hairscut, more a trim than anything else.
Before I start going into the details, let me tell you how complicated I am about cutting my hair. I have curly hair. I used to have short hair when I was basically 15, and then I start having very long hair. Because my hair is curly, the more it grows, the more it gets curly, masking the real length. Anyway, at some point it gets unruly, so you have to cut it back.
I used to go to the same barber for years. He is based in my parents’ village and I tend to go there to have a haircut when I’m back in Italy. Half of my friends think that is totally insane to have a barber that is more than 4000 Km away from where you currently live; the other half instead they completely agree, and they would not change their barber/haridresser ever. Nobody else could even grasp how to do your hair.
Let’s dive in, then..
I was walking on Stroud Green, which has an hairdresser/barber every 3 shops, and I was toying with the idea to have a small trim, so I could have a decent situation until December, where, given I was going back to my parents place for Christmas, I could have the proper cut(tm).
I decided to enter a barber shop. My belowed reader,Ā this is going to get interesting real fast :D.
I enter the barber shop, and ask if there is a space. One guy is already working on another customer but he tells me there is space: the chair is free and another guy is basically getting ready to start working. (It’s very early in the morning).
My barber is called Ozi (I think..). He asked me how I want my hair cut. I tell him I want just a trim, to have a more precise and ordered head.
He shows how much he understood he has to cut, using his hand to show the length. I tell him I would like them a bit longer. He gets it the other way around, and he thinks I want longer the part that he has to cut!
After some other brisk exchanges, it seems an agreement is reached.
He starts using some water spray to wet my hair. I am a bit confused by that.. I thought he was going to wash them so I ask him:
Me: “No wash?”
Him: “No wash!”
Me: “No wash??”
Him: “No wash.”
Me: “Maybe wash?”
Him: “Wash?”
Me: “Yes, No?”
He puts the bottle down, opens the tap in the sink in front of me, and then he basically drops me in the sink. I even didn’t realize what is happening that basically I’m making bubble in the sink trying not to drown, when this guys is washing my hair in a very energetic way.
Close to my breath running out, the water stops, and I came back to breath again. Ozi takes a towel and starts to dry my hair, using a decent amount of force, because of which I honestly worry about my neck muscles.
He starts to cut my hair, and goes on for a good bit. He asks me if I want a trim on the side and I agree to it. I start being suspicious that he is cutting quite a bit, so I try to understand how much he cut (when my hair is wet, basically it’s quite difficult to assess the length.)
I look at my hair.. and I say:
“This is very short! You cut a lot!”
He replies: “sorry boss!” and he continues to cut my hair!
Oh well, the situation went out of control, so I decide that I can’t really do anything about it, and accept my look change.
The beard business
He asks me if I’m interested in him cutting my beard, and I accept the offer. He asks me if I’m interested to let it growth, and I say yes. So he asks me which settings should he use and I propose a 7…
He looks at me extremely puzzled. More over one of his collegues comes over as well, he test the lenght of my beard with his hand and he says, “I’m sorry boss, but this is 2, max 3. I think our machines are bigger”.
I looked at them, I take a quick peak at their machine and I agree that could be the case, so we settle on 3.
The machine just gently trims very tiny amount of the bead. When he is happy with the result, he picks a serious hard-core brush and he brushes my beard. I have to confess that I never done that before. I’m amused.
After that he asks me where I want the neck line. I never did one before, so I just tell him to go ahead, and he makes the line using a cutthroath razor. He cuts me in a little part, he picks some septics and then he applies it to the wound. It’s a real close shave.
At this point I’m quite lost, I do not know what to expect next. Ozi takes some kind of mask, and it applies on my face. I’m sporting a mask. First time. Ever…
However the surprises are no finished. Ozi takes a small little piece of metal with some cotton at the end, that looks like a little torch. He switches it on with a lighter and we have an honest flame in the shop, just in front of me.
He blows it away and then he uses the hot metal to burn the hairs on the outside of my ears! First time again that something like this happens.
He takes some small scissors and he also cuts the hairs in my nose; I’m still wearing a mask, and it is clear that I’m completely lost to the unfolding of the events, and I’m watching the happening with a sort of spectator detachment at this point, and decent amount ofĀbewilderment.
Before I can truly realize what is happening, I’m again in the sink, where he washes my hair (again) and also the mask cream from my face. This time I’m a bit better at catching some breaths here and there, so the drowning possibility is a bit less concrete.
The wash concludes and I get back, sitting on the chair again. At this point aĀhot towel shows up. Ozi wraps it around my face, leaving a tiny hole, so I can breath through my nose.
While I am there thinking that is nice to relax like that, out of nowhere my right arm gets lifted and quickly rested upon a support integrated with the chair that just slided out of nowhere. Ozi is massaging my arm!
I’m like: What is happening here today? I do not really know. Ozi goes on to the other arm and I get also that one massaged.
The not so hot anymore towel gets removed, and Ozi takes some container. I think it may contain wax, and he is gonna put it on my hair. I think he may just do it without asking me, however I also recognize that this whole business is out of my control for quite some time, so I’ve made peace with my destiny and I’m waiting for the wax.
Of cours it isĀnot! It’s cream! Not a mask cream, but some moisturizing cream that he puts on my face.
He then asks me if I want some gel. I say no to the gel. It’s time to make some choices :D.
It’s the end. I stand and I look at myself. Basically all my hair has been cut, my beard is phenomenally shining, and I look so different from when I’ve entered!
I pay, and just on the door, the other guy tells me goodbye sexy!
So here it is. I hope you enjoyed the story, I truly had fun during it.
As usual, Merry Xmas and Happy New Year! I hope you enjoy the decorations :DĀ