Apollo running latest Ubuntu
TL;DR: Get it.
I’m a Linux user for a long time, which is so long that I still know the difference between GNU/Linux and Linux.
My first distribution, jut right off the bat, was a Gentoo, where I was compiling kernels and everything else to have a working system. Having very few idea of what I was doing.
This usually meant having to fight with drivers, search for solutions on forums (sometimes very hidden once) and be a quite technical person.
I have to say I have learned a lot during this time, and actually Linux made me interested again in computer and informatics in general.

Long time ago, in far far away galaxy recompiling the kernel was normal, even if you didn’t know what the kernel was!
Time passed and several revolutions do have happened; first, the Ubuntu distributions was founded, and I think it really helped to bring Linux closer to the masses. Of course one of the good ideas was to use Debian as base, however I think the time spent in bringing a coherent user interface towards the general public was what Ubuntu was striving for. The bug number one was closed long time ago, mostly due to the increase of portable computing, and the part that Android has played into it, although I still think that Ubuntu has played a big part.
Second, a big shift on the laptop environment also materialized. Dell was one of the first big retail name to provide a Linux solution laptop, and in particular the XPS 13 which was always a good computer. Dell was offering to have Ubuntu pre-installed directly from the factory, and that was the choice I made. I had the old XPS, and I had a good experience with it. which meant no license Windows fee. I’ve got one. The motherboard suffered quite a bit of hiccups, but all in all the laptop did its job valiantly.
The new XPS 13 inch looks pretty good, and the project Sputnik is entirely devoted to make sure this laptop runs Ubuntu or other distributions properly. While the XPS 13 is a terrific laptop, two main problems didn’t let me pick it. First: the position of the video camera. I get the small bezel idea and stacking a 13 inches display in what usually it’s a body of an 11 inches is great for portability, however the angle of the camera is desperately bad.
Basically, if you have a video call with somebody, they see the internal of your nose, instead of your fact. If video call are a day to day experience for you, it cannot be an option.
The second problem is the screen. While the colours are amazingly brilliant and the resolution so high that you need a lens to see the icons, the major problem is that in most of the high level configurations you have only the glossy option available
A glossy display reflects all the lights, so even a little sun-ray that hits that screen will turn it into a mirror, with the clear result of decreasing the usage of it. Basically you can’t see what is going on. And that is bad.

With latpots, either you don’t care, or you get extremely opinionated.
So that brings me to the Apollo by Entroware.

Apollo 13 inches, sleek and nice.
A very nice in depth review has been done by the Crocoduck here, so I suggest to visit it there. Here I’m gonna put my general impressions.
Apollo laptop impressions
When you power up the laptop via the dedicated power button which is integrated in the keyboard, you are greeted by the Ubuntu installer. Partitions and most of the stuff is already done for you, what you’ve got to do is to pick is the username, and the timezone.
After that you are greeted by a standard Ubuntu installation. Everything goes out of the box, in particular:
- Wifi can just be used via Network Manager
- USB port are working: I have even bought a USB 3.0 to ethernet dongle, and it was just plug and play
- All the Fn keys (backlit keyboard, Bluetooth, screen brightness and so forth) do work.
- Suspend works out of the box, without any problems. I’ve noticed that the wifi sometimes does not get back properly, but it easily fixed restarting network-manager :
systemctl restart network-manager.service
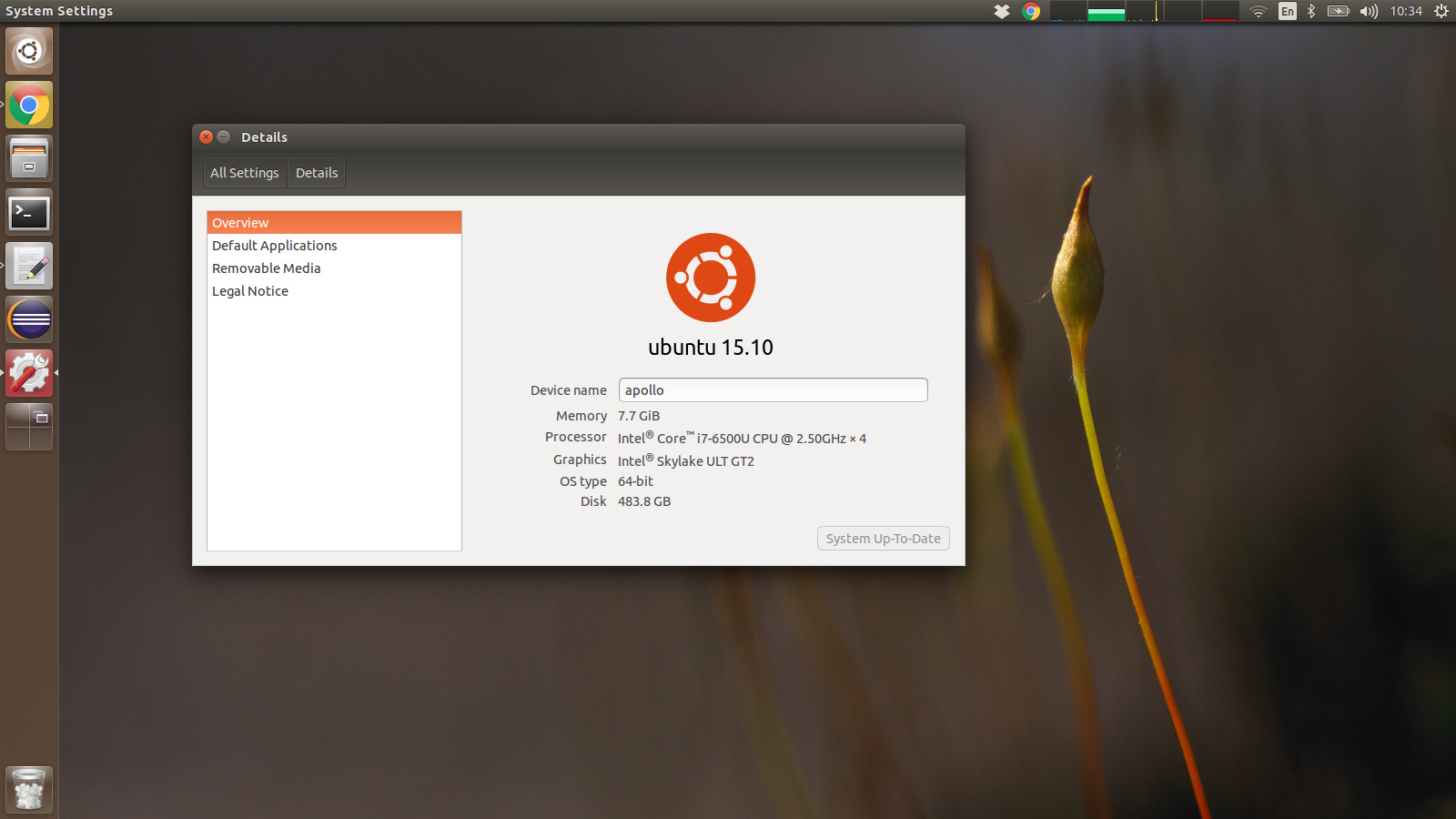
Specs: i7 CPU on skylake bridge, 500 Gb SSD, 8 Gb RAM, with a 1920×1080 display (which I run @ 1600×900 to actually have a bigger text), weighting a bit less than 1.5 Kg. Everything for £824, which is a honest prize I think.
The keyboard is very comfortable and nice. The keys do have a nice feeling and it’s not tiring to write on it. The touchpad is ok, the tap works great and the sensibility looks good. Clicking is doable, however it’s one of this integrated touchpad, so it will never be as good as a normal touchpad with physical buttons.
So if you are in the market for a sleek portable laptop running linux, I totally suggest to check the Entroware laptops.